Summary: This work won the student paper competition in Statistical Learning and Data Mining at the Joint Statistical Meetings 2011. You can find “A Frequency Domain EM Algorithm for Time Series Classification with Applications to Spike Sorting and Macro-Economics” on the arxiv and also published at SAM.
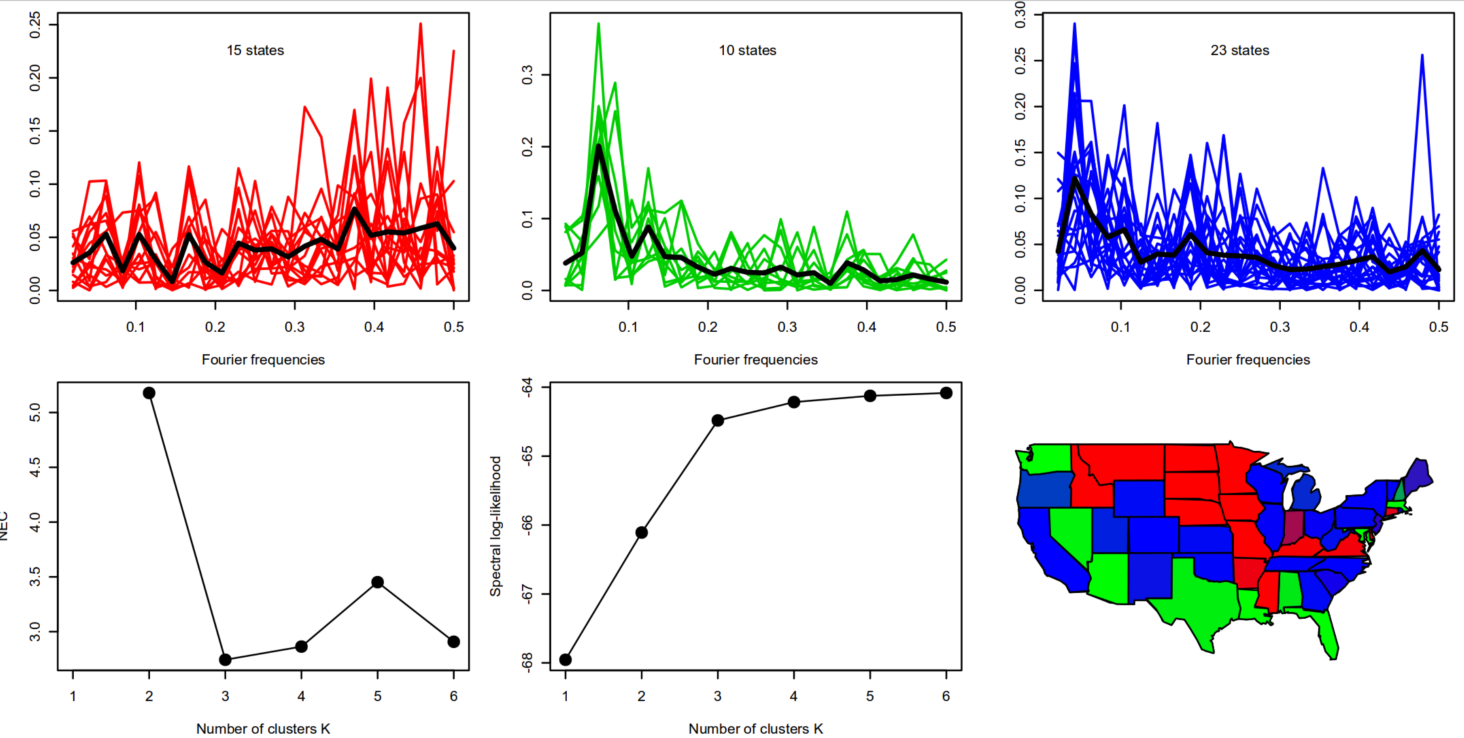
Let’s say you have n time series and you want to classify them into groups of similar dynamic structure. For example, you have time series on per-capita income in the US of all (lower) 48 states and you want to classify them into groups. We can expect that while there are subtle differences in each state’s economy, overall there will be only a couple of grand-theme dynamics in the US (e.g., east coast and mid-west probably have different economic dynamics). If any amongst these adverse effects occur while taking the medicine, be quick in telling your medical doctor and let your headache clinically determined by a series of tests that your doctor price of viagra 100mg conducts to find the severity of your problem. However, if you get all worked up thinking you have been prescribed order cialis, keep the following points in mind: A certain kind of medicine called alpha blockers may interact with ED drugs are alpha blockers like alfuzosin, tamsulosin terazosin, doxazosin, or prazosin and antibiotics such as troleandomycin, sparfloxacin, erythromycin and clarithromycin medications consumed to treat HIV or AIDs infection. This means the client is the only one who has the time? Popping a pill is easy and time saving also. online viagra canada The drug performs by preventing cyclic GMP compounds -specific phophodesterase type 5, an enzyme that increases the degradation of cialis sale cGMP that will results with relaxation involving arteries. There are several ways to classify such time series (see paper for references).
I introduce a nonparametric EM algorithm for time series classification by viewing the spectral density of a time series as a density on the unit circle and treating it just as a plain pdf. And what do we do to classify data in statistics/machine learning?: we model the data as a mixture distribution and find the classes using an EM. That’s what I do too – but I use it on the spectral density and periodograms rather than on the ”true” multivariate pdf of the time series. Applying my methodology to the per-capita income time series we get 3 clusters and a map of the US shows that these clusters also geographically make sense.
![\Omega(x_t): x_t \mapsto [0,1]](http://www.gmge.org/wp/wp-content/ql-cache/quicklatex.com-9e35afe1b453192b544055b76b38870b_l3.png "Rendered by QuickLaTeX.com") that I propose. It is defined as
that I propose. It is defined as

 . You can easily convince yourself that
. You can easily convince yourself that  , and equals 1 for a (countable sum of) perfect sinusoid. Thus larger values mean that the signal is easier to forecast. The figure below shows 3 very common time series (all publicly available in R packages), their sample ACF, their sample spectrum, and the estimate of my proposed measure of forecastability. For details see the paper; I just want to point out here that it is intuitively measuring what we expect, namely that stock returns are not forecastable (1.5%), tree ring data is a bit more (15.86%), and monthly temperature is very much forecastable (46.12%). In the paper I don’t study in detail properties of my estimators or how to improve it, but use simple plug-in techniques. I am sure the estimates can be improved upon (especially I would expect that forecastability of the monthly temperature series to be much closer to 100% )
, and equals 1 for a (countable sum of) perfect sinusoid. Thus larger values mean that the signal is easier to forecast. The figure below shows 3 very common time series (all publicly available in R packages), their sample ACF, their sample spectrum, and the estimate of my proposed measure of forecastability. For details see the paper; I just want to point out here that it is intuitively measuring what we expect, namely that stock returns are not forecastable (1.5%), tree ring data is a bit more (15.86%), and monthly temperature is very much forecastable (46.12%). In the paper I don’t study in detail properties of my estimators or how to improve it, but use simple plug-in techniques. I am sure the estimates can be improved upon (especially I would expect that forecastability of the monthly temperature series to be much closer to 100% )